Hi,
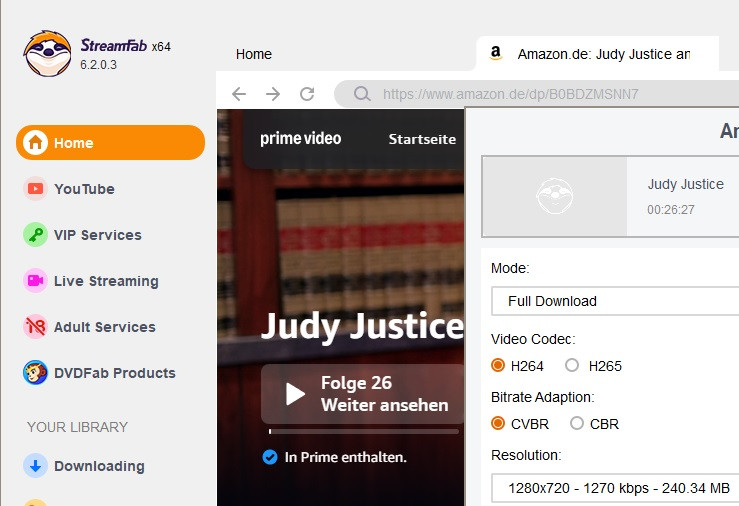
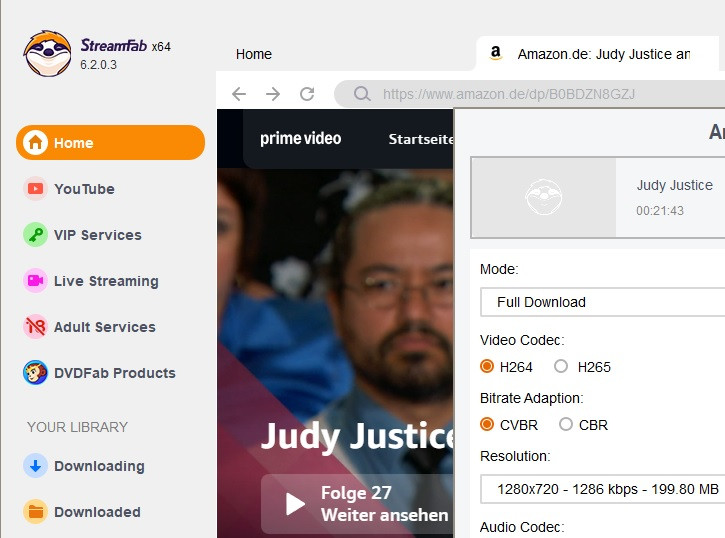
Please try the test version for the Amazon 25 episodes problem.
Wilson.Wang
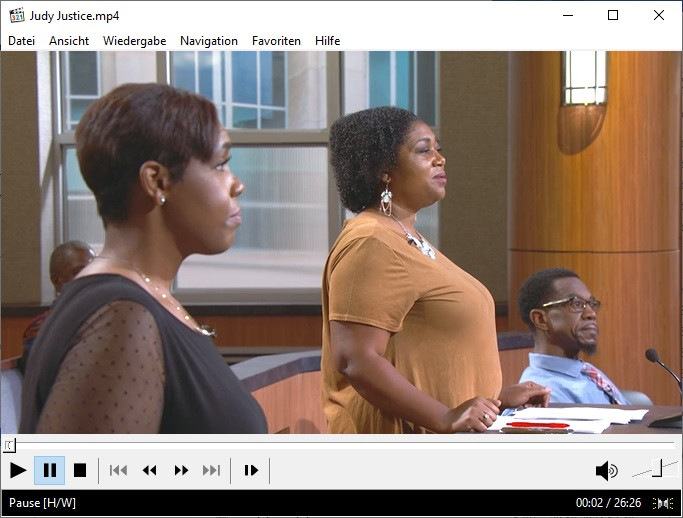
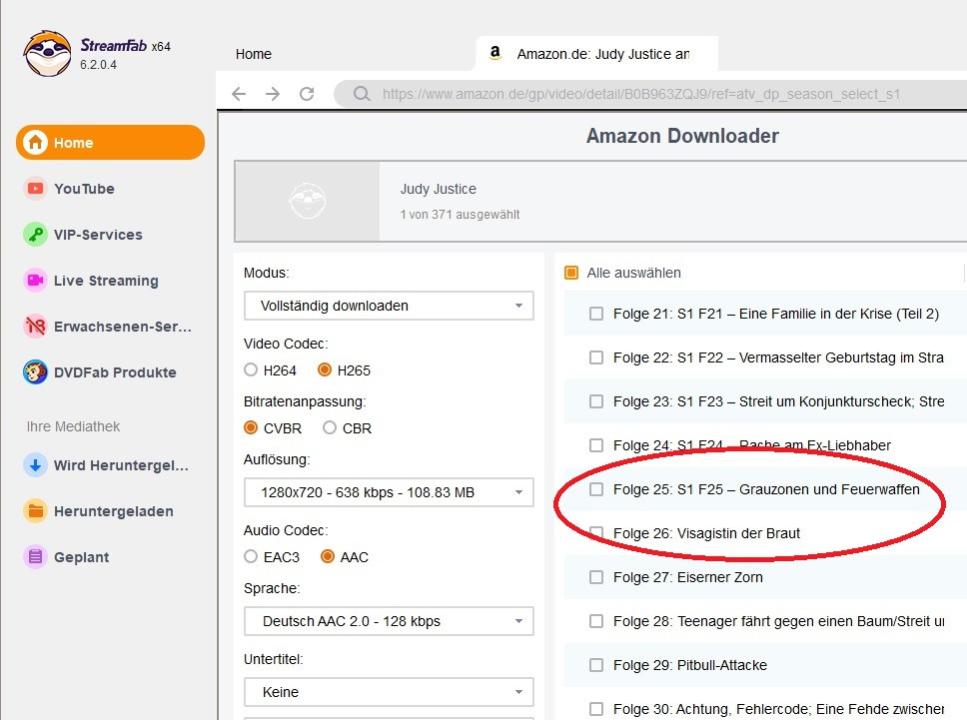
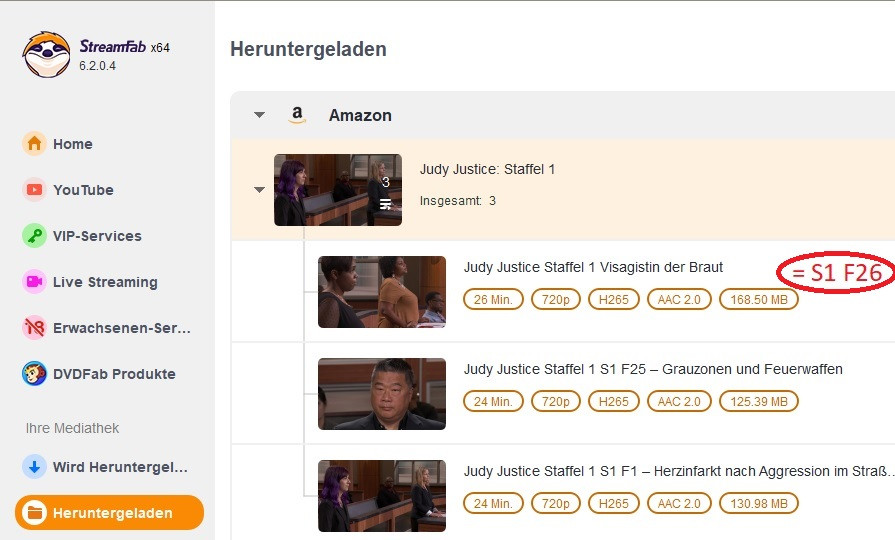
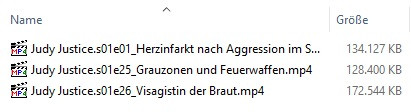
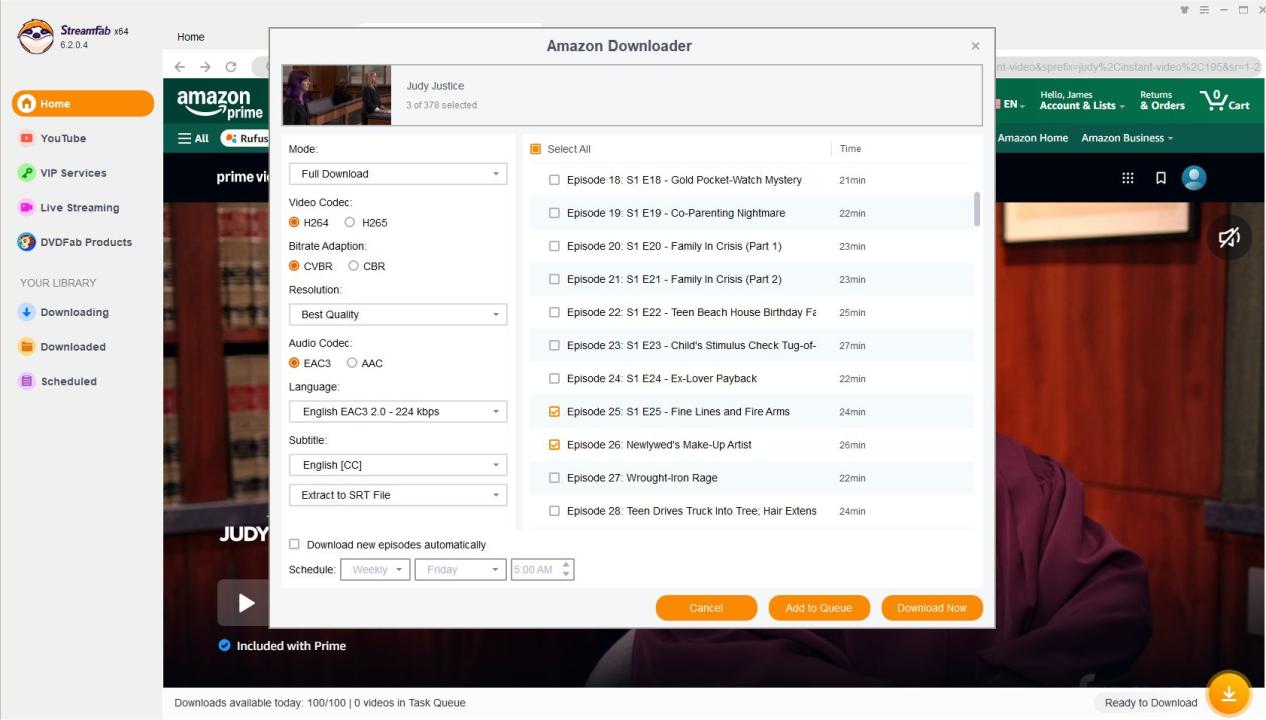
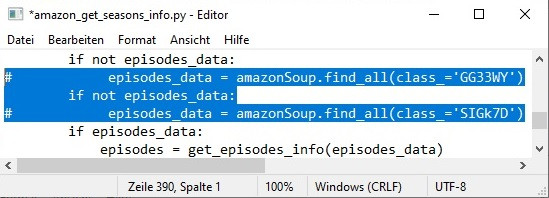
Works great at pulling the episodes but (and I'm guessing here) the way that it's engineered at the moment (and I appreciate it's a test to see if it works in the first place) SF gets the first list of episodes from the initial page then looks at the template for the token and requests additional episodes using the token, then parses the JSONised response and adds those episodes, resulting in weird behaviour where episode numbers are doubly messed up, e. g.:
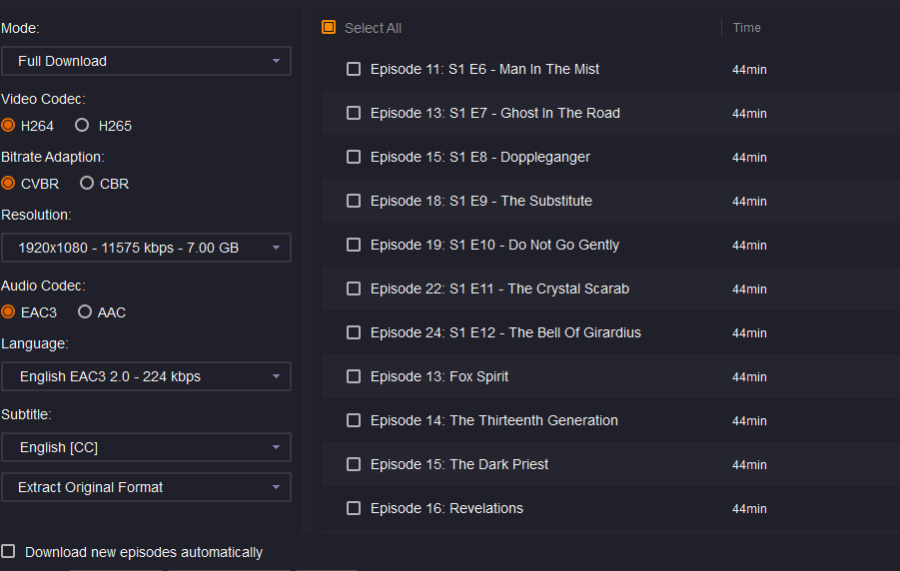
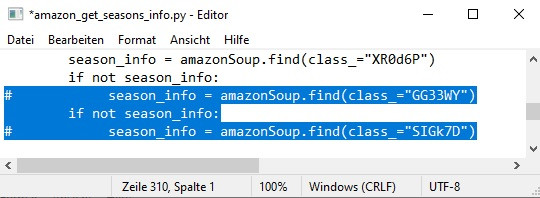
Would it not be much simpler to take the episode list from the template, check if there's a pagination token, if there is then request the additional (26+) episode list, add that episode list to the initial episode list we got in the initial template, and then parse the whole combined (much simpler) JSONised list of the episodes? And if there isn't a pagination token, you still just parse the JSONised episode list (because the size of the list doesn't really matter). That way you have a single single-pass JSONised episode list parser just with a D-tour if there's pagination, instead of having an HTML episode parser followed by a JSONised episode parser if there's pagination, i. e. you won't need get_episodes_info() at all, or make it just parse JSON instead?