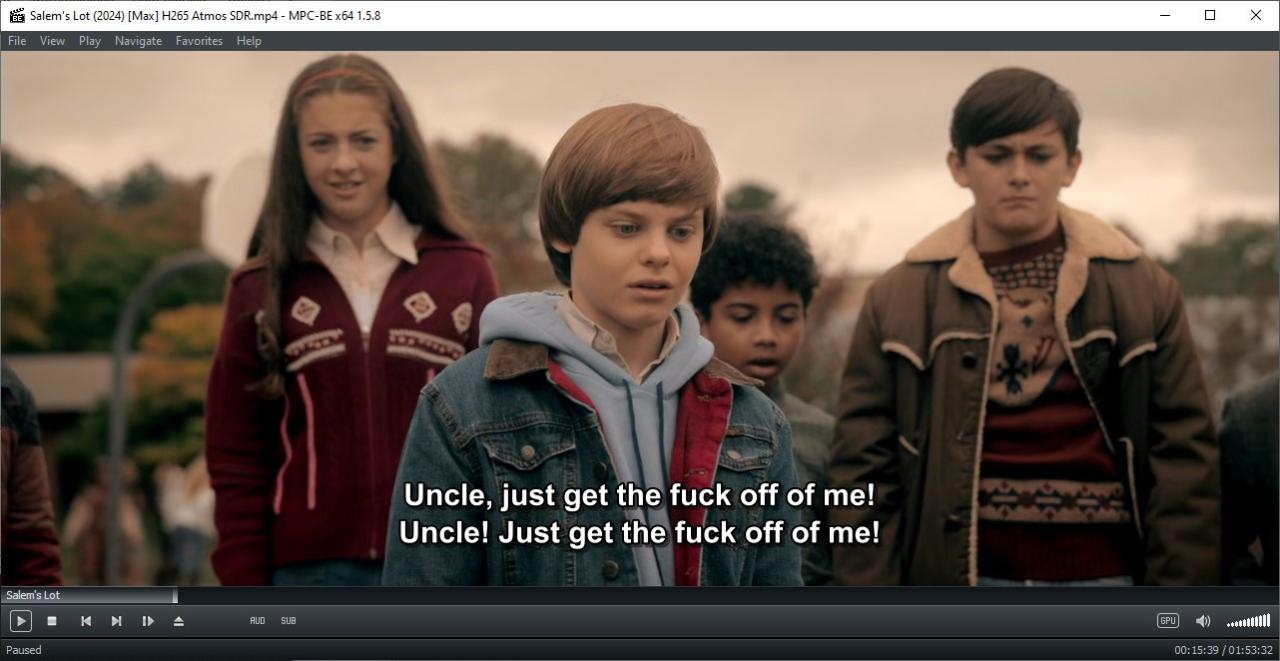
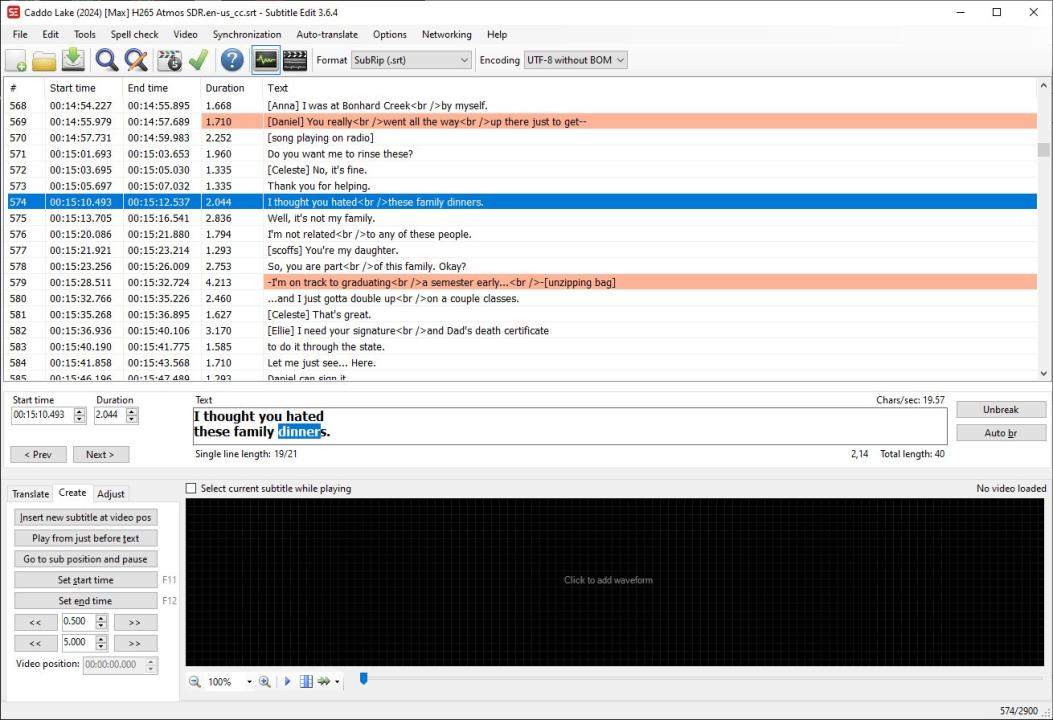
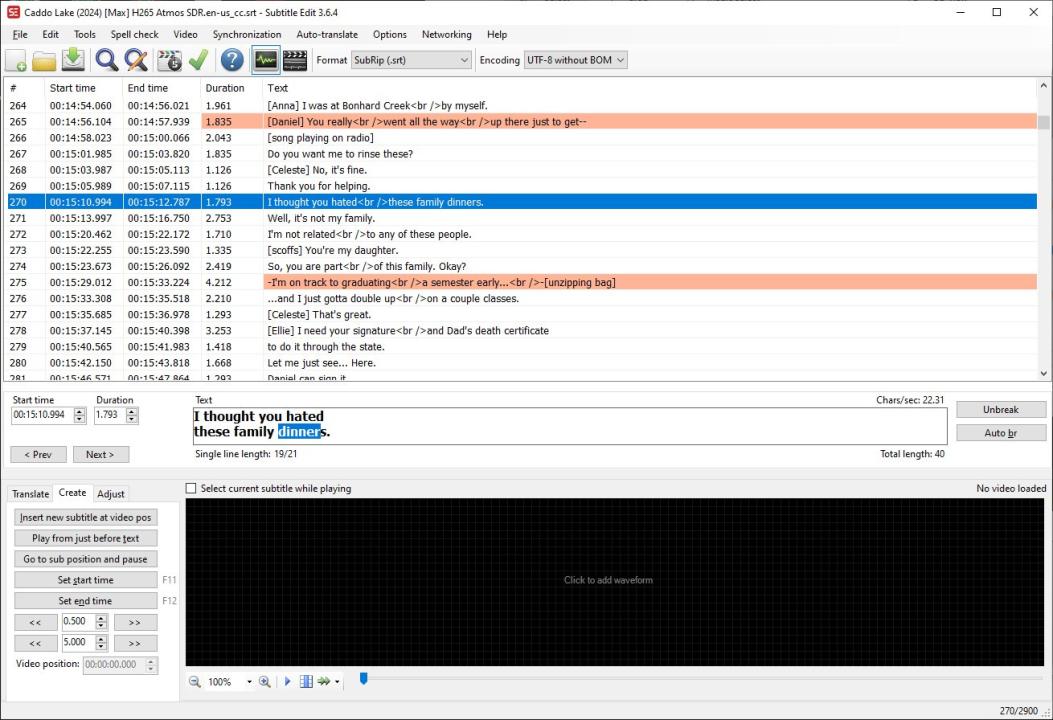
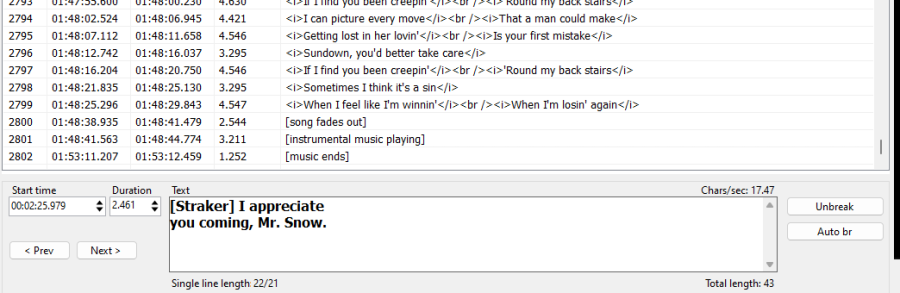
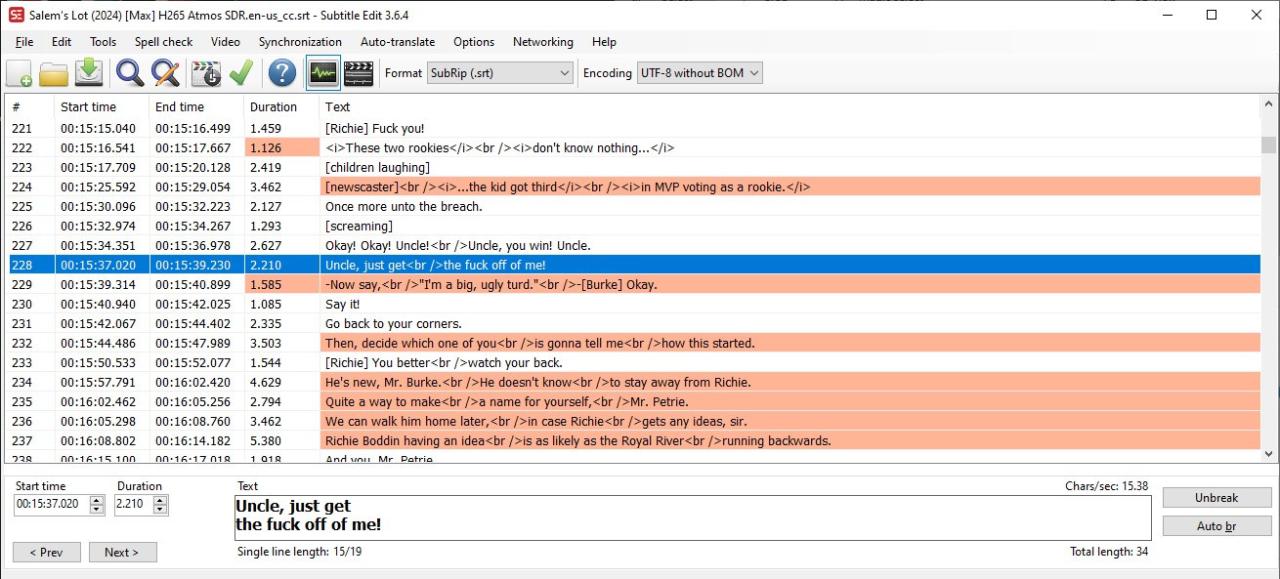
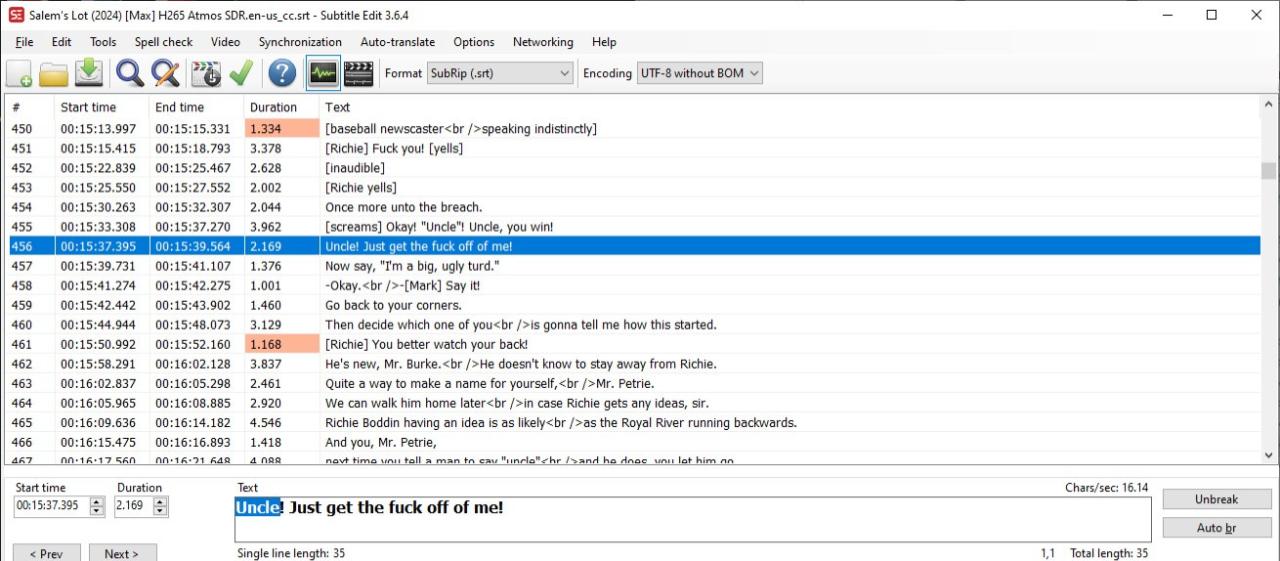
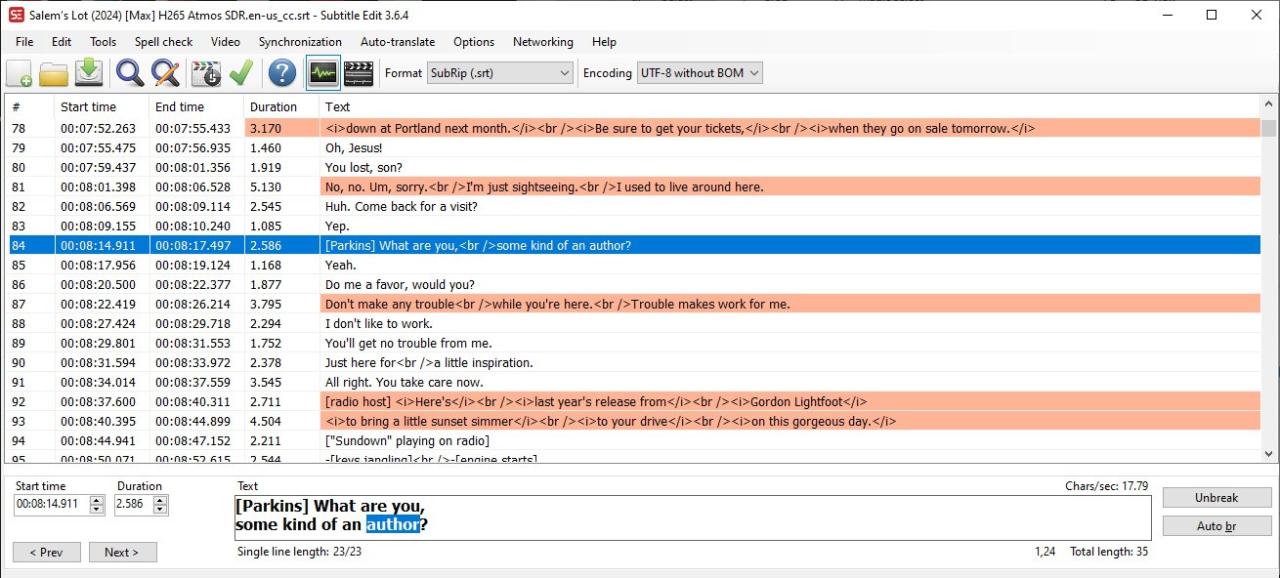
This problem has been fixed in 6.2.1.4 but how about detecting / fixing the (already downloaded) subtitles from previous versions?
I present a script that will (try to) do both.
It requires Python 3.10+ and 'srt' and 'chardet' libraries (installed via 'pip install').
The instructions follow:
Fix Max srt subtitles downloaded by StreamFab versions 6.2.1.3 and earlier
Some of these files have repeating, overlapping blocks of subtitles coming from
two different sources, so they are not exact duplicates.
This problem affects mostly English subtitles but who knows what else...
Fortunately, the timestamps are grouped together between the two variants, so that
by analyzing negative time jumps conflicts can be detected automatically;
this script attempts to do just that.
This may backfire in rare cases but should be 99% safe.
The script should be executed with either
- directory name, to be traversed recursively for all the srt files inside
or
- srt file name
The fix comes with 2 variants: two srt files will be saved with filename ending with
'.fixed.v1.srt' and '.fixed.v2.srt'. The variants differ by which set of conflicting lines
got removed (v1 removes the former and v2 the latter of the two conflicting groups of lines).
The code is pasted below (I prefer not to attach files as I don't know if these will be visible). Feel free to do whatever you like with this code, hopefully it will be useful.
#!/usr/bin/env python
# this script requires at least Python 3.10
help_string = \
"""Fix Max srt subtitles downloaded by StreamFab versions 6.2.1.3 and earlier
Some of these files have repeating, overlapping blocks of subtitles coming from
two different sources, so they are not exact duplicates.
This problem affects mostly English subtitles but who knows what else...
Fortunately, the timestamps are grouped together between the two variants, so that
by analyzing negative time jumps conflicts can be detected automatically;
this script attempts to do just that.
This may backfire in rare cases but should be 99% safe.
The script should be executed with either
- directory name, to be traversed recursively for all the srt files inside
or
- srt file name
The fix comes with 2 variants: two srt files will be saved with filename ending with
'.fixed.v1.srt' and '.fixed.v2.srt'. The variants differ by which set of conflicting lines
got removed (v1 removes the former and v2 the latter of the two conflicting groups of lines).
"""
import os
import sys
import glob
import srt
from chardet.universaldetector import UniversalDetector
detector = UniversalDetector()
append_fixed_v1: str = ".fixed.v1"
append_fixed_v2: str = ".fixed.v2"
def fix_srt(filename: str, srt_input: str, threshold: float = -30.0) -> tuple[str, str] | None :
"""Fix srt_input given as a string
:param filename: name of srt file (used only for reporting)
:param srt_input: srt subtitles as a string
:param threshold: minimal negative time jump (in seconds) to consider as needed to be fixed
:return: a tuple of fixed srt subtitles (two variants of a fix), or None if no fix is needed
"""
try:
# get a list of subtitles from the contents of srt file
subs: list[srt.Subtitle] = list(srt.parse(srt_input))
except:
print("file:", filename)
print(" ... could not parse srt contents (probably encoding-related problem)")
print(f" ... encoding detected: {detector.result}")
return None
# detect indices where time jumps backwards between two consecutive lines
diffs_negative: list[int] = []
for i in range(len(subs)-1):
if (subs[i + 1].start - subs[i].end).total_seconds() < threshold:
diffs_negative.append(i)
# if there are such negative jumps, fix by removing the conflicting subs
if diffs_negative:
# contains indices of subs to keep,
# removing the sub is done via removing its index from this list first
indices_v1: set[int] = set(range(len(subs)))
indices_v2: set[int] = set(range(len(subs)))
## variant 1 of the fix:
# index_end is where the time jump occurs
for index_end in diffs_negative:
# determine index_start
timestamp_start_bound: float = subs[index_end + 1].start.total_seconds()
# ... starting from the end and going backwards,
# find the line with timestamp early enough for subtitles to not overlap
index_start: int = index_end
while ( index_start >= 0
and subs[index_start].end.total_seconds() >= timestamp_start_bound
):
index_start -= 1
# the line with index_start is the first one not overlapping,
# so skip to the next one
index_start += 1
# remove subs with indices from index_start to index_end,
# which is the minimal amount to remove so that there is no more
# jumping backwards in time between consecutive subs
for i in range(index_start, index_end+1):
if i in indices_v1:
indices_v1.remove(i)
## variant 2 of the fix:
# index_start is where the time jump occurs
for index_start in diffs_negative:
timestamp_end_bound: float = subs[index_start].end.total_seconds()
index_start += 1
# determine index_end
# ... starting from index_start and going forward,
# find the line with timestamp late enough for subtitles to not overlap
index_end: int = index_start
while ( index_end < len(subs)
and subs[index_end].start.total_seconds() <= timestamp_end_bound
):
index_end += 1
# the line with index_start is the first one not overlapping,
# so skip to the next one
index_end -= 1
# remove subs with indices from index_start to index_end,
# which is the minimal amount to remove so that there is no more
# jumping backwards in time between consecutive subs
for i in range(index_start, index_end+1):
if i in indices_v2:
indices_v2.remove(i)
subs_filtered_v1 = [subs[i] for i in sorted(list(indices_v1))]
subs_filtered_v2 = [subs[i] for i in sorted(list(indices_v2))]
try:
print("file:", filename)
srt_output_v1: str = srt.compose(subs_filtered_v1,reindex=False)
print(f" ... srt contents fixed, variant 1: a total of {len(subs)-len(subs_filtered_v1)} lines removed")
srt_output_v2: str = srt.compose(subs_filtered_v2,reindex=False)
print(f" ... srt contents fixed, variant 2: a total of {len(subs)-len(subs_filtered_v2)} lines removed")
return (srt_output_v1, srt_output_v2)
except:
print(" ... srt.compose internal error, cannot re-parse subtitles")
print(f" ... encoding detected: {detector.result}")
# there is nothing to do (file is already ok / not corrupted)
# print("file:", filename)
# print(" ... no problems detected, no fix needed")
return None
def fix_file(filename: str) -> bool:
"""
Fix SRT file
:param filename: full path to the SRT file
:return: True if fixed, False otherwise
"""
filename_v1 = filename[:-4] + append_fixed_v1 + '.srt'
filename_v2 = filename[:-4] + append_fixed_v2 + '.srt'
if os.path.exists(filename_v1) or os.path.exists(filename_v2):
print("file:", filename)
print(" ... fixes already exist, skipping")
return False
else:
# (try to) detect the correct encoding of a file, pure magic this!
detector.reset()
try:
with open(filename, 'rb') as f:
for line in f:
detector.feed(line)
if detector.done: break
detector.close()
encoding: str = detector.result['encoding']
except:
print("file:", filename)
print(" ... !!! ERROR cannot read file contents in binary mode (file access problem?), skipping !!!")
try:
with open(filename, 'r', encoding= encoding) as f:
srt_txt = f.read()
except:
print("file:", filename)
print(" ... !!! ERROR cannot read file contents, skipping !!!")
print(f" ... encoding detected: {detector.result}")
return False
# generate two variants of a fix
fixes: tuple[str, str] = fix_srt(filename, srt_txt)
# if fixes occurred
if fixes:
srt_fix_v1, srt_fix_v2 = fixes
try:
with open(filename_v1, 'w', encoding= encoding) as f:
f.write(srt_fix_v1)
with open(filename_v2, 'w', encoding= encoding) as f:
f.write(srt_fix_v2)
return True
except:
print(" ... !!! ERROR occurred while writing files with fixes !!!")
print(f" ... encoding detected: {detector.result}")
if __name__ == "__main__":
# Test the amount of arguments
if len(sys.argv) != 2:
print("Exactly one argument required")
print(help_string)
sys.exit(-1)
arg = sys.argv[1]
# Traverse the directory if given as an arg
if os.path.isdir(arg):
print(f"Traversing directory '{arg}'...")
for filename_relative in glob.iglob("**/*.srt", root_dir=arg, recursive= True):
filename = os.path.join(arg, filename_relative)
if os.path.isfile(filename):
fix_file(filename)
# ... or just fix the file if given as an arg
elif os.path.isfile(arg):
if not fix_file(arg):
print("file:", arg)
print(" ... fix not applied / not needed")
# cover the edge case
else:
print(f"'{arg}' is neither a file nor a directory")
print(help_string)
sys.exit(-1)
print(" ... DONE!")